
Feature stores are the rage in the advancing world of AI and machine learning.
Before we learn what is a feature store, we must understand the features of machine learning.
Features for Machine Learning
Consider machine learning or MLOps for models that make predictions – you will need features to feed them with.
What are features in ML?
Features are individual measurable characteristics or properties of a phenomenon under observation. The feature, in reality, is data used by the machine learning models; for instance, that data can be pixels in a picture or rows and columns in an excel sheet.
Features as Fuel for ML
A powerhouse for Ml/AI systems, the features are utilized for training machine learning models for making predictions. But, predictions need massive features or data; the more data, the better the predictions will be.
Feature Organization
The data or features need to be organized to make sense.
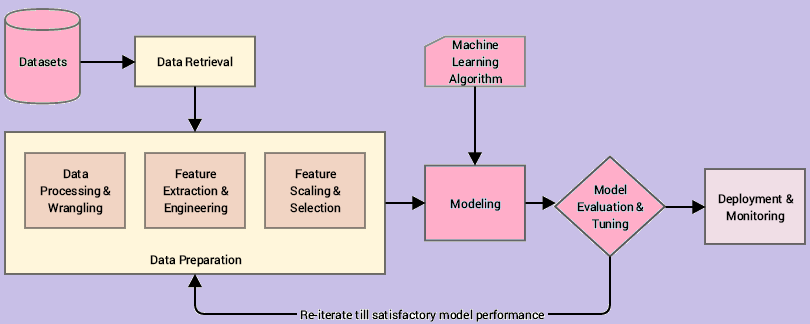
Data for features are pulled from the data source and are required to be stored after computation – feature engineering is the transformation of source data into features.
Ready-made Datasets
ML needs ready-made datasets of features for training models correctly.
Datasets mean that the features can be typically accessed as files in the file system. Plus, you can read features directly as data frames via the feature store.
What is a feature store?
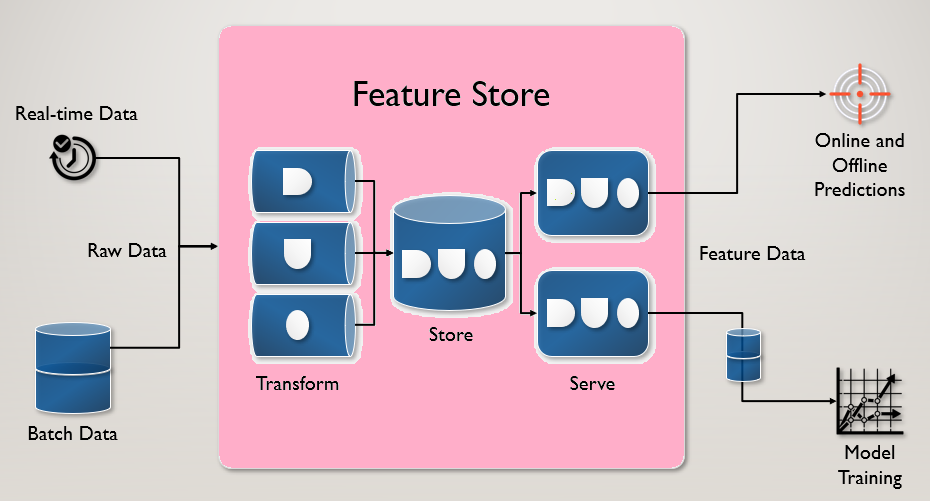
A feature store is where the features are organized and stored for use in training models or making predictions by application with a trained model.
To sum up the query of what is a feature store, it is a central location where you update or create groups of features – features that are created via multiple data sources. Also, in feature stores, one can create or update these feature groups to train models for use in application, that do not compute features but rather retrieve them when they need to make predictions.
First Feature Store
The first ever feature store was from Uber in 2017 – its purpose was to facilitate documentation, discovery, and reuse of features and to guarantee the correctness, whether used by online or batch applications.
Here is where a feature store comes in machine learning applications:
How will a feature store make the ML lifecycle easy?
In technical terms, a feature store offers;
- Reliable feature engineering for data training and serving
- Feature reuse
- System support for feature serving
- Tentative data analysis
- No data leakage – point-in-time training data
- Governance and security if features
- Reproducibility of training datasets
Now that we know what is a feature store and how its integration can make our lives easier, let’s discuss where feature stores are headed.
Feature Stores Future and Challenges
Today when tech giants are innovating ML as an essential part of the business, there arise some obstacles to the conventional approach to ML:
- The data scientists are spending excessive time transforming data before they begin building models
- Even worse, when they start with a new use case, there is often no clean data for use.
- The notebook base data makes it hard to track and manage the data being used. Also, it is unclear how to tackle the work in a notebook and transform it into a production job.
- People who are not data scientists have close to no chance of achieving anything with ML tools.
- Offline and online requirements lack a unifying data layer
Feature Store Integration for Machine Learning
Feature stores are available in different packages.
Be it with an online database, or virtual feature stores, which do not have any database – FeatureForm. Also, some feature stores are firmly integrated with a single Data Warehouse, etc.
Every feature store offers various solutions for plugging in pre-existing enterprise data infrastructure and ML tooling.
A feature store is perfect to fit in an enterprise infrastructure consisting of operational and analytical data. Operational data apps drive business, and analytical data is a data warehouse or a datalake which stores massive volumes of data needed to analyze and optimize business.
ELT or ETL data pipelines extract the data from operational datastores, transforming it and writing it to the data warehouse. Many enterprises aim to productionize artificial intelligence as a starting point to start with analytical data, build feature pipelines and produce training data for the models and features in batch scoring.
What is a feature pipeline?
Feature pipelines in ML are similar to data pipelines; however, instead of output being the rows in a table, the output data is validated, aggregated, and transformed into a suitable format for input to a model.
Feature Store Challenges in Machine Learning
With the advantages of feature stores in ML also come some challenges;
- Machine learning algorithms are sensitive to bad data; therefore, the data needs to be validated.
- The data often also needs to be aggregated as the features are compressed over many data points, for instance, the number of credit card purchases in a given period.
- Machine learning models also expect well-formed numeric data input. The input data must be transformed into the format that the model expects and is scaled to enable model coverage in training.
- Output is not always backed to analytical data stores in feature pipelines. Sometimes the features are required in the operational data stores. For instance, building a user-facing application retrieves pre-computed contextual or historic features at runtime, enriching feature vectors.
For a working and scalable feature store and ML tooling solutions, get in touch with Qwak – your partner towards business success.